


Many Bets, A Few Big Payoffs
And Compressing The Investment Timeframe
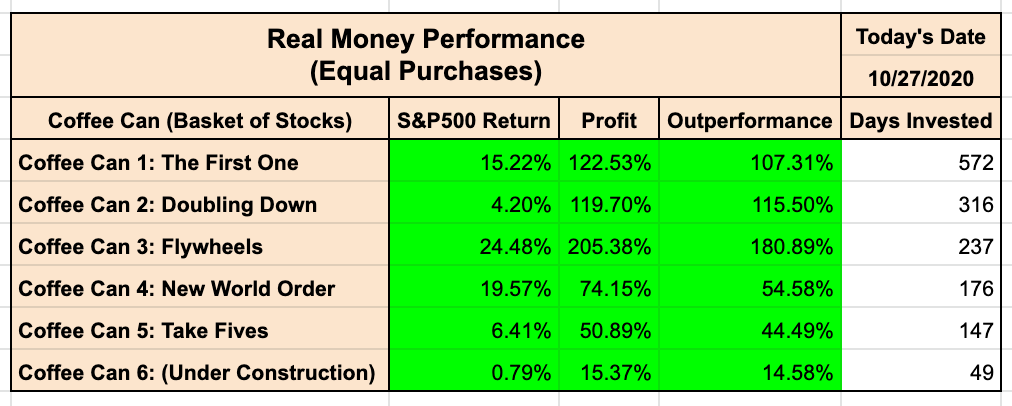
I am a big fan of the Coffee Can Portfolio, an “Active Passive” approach to investing. The idea is simple: You try to buy a basket of the best stocks you can and let them sit for years. You incur no costs with such a portfolio, and it is simple to manage.
My stock baskets can be found here on my Scorecard. Coffee Can 6 remains under construction.
Investing in Mavericks is an investment strategy that brings the Venture Capital approach to the Stock Market. This approach is really about betting on businesses benefiting from “significant changes in the status quo”. Tesla is a perfect example. If we are right about some of these businesses, we can benefit immensely from Power Law dynamics and make wonderful returns. Such returns however, often take a very long time to materialize.
What if we could compress these time frames?
This is where Options come in. Option price movements also seem to follow a power law distribution, but they do so in much more compressed timeframes. Options can expire in as little as just a few days to as long as only ~2 years. As a result, the feedback loop between making an investment and waiting for a result can be quite short.
Note: If you’re new to Options, you can quickly learn the basics here: Option Basics 1 and Option Basics 2.
In my view, buying options is very similar to investing in a Disruptor. Both stand before a myriad of possible payoffs, some bad, some good, some amazing. Disruptors, like options, are also time-sensitive assets, especially earlier in their existence. If they are unable to demonstrate product-market fit, they will soon cease to exist.
If this is the case, can we apply the Venture Capital mental model to Options as well?
At the moment, I’m not sure. But, answering this question is the basis of my latest Sandbox Experiment.
My Latest Experiment
Hypothesis:
In order to successfully apply the Venture Capital mental model to Options, we need to build an algorithm, one that makes several bets, one that tries to stay neutral to slightly negative with most of those bets, but one that ultimately requires at least a few extremely large positive payouts.
Although the rules that govern such an algorithm may not be fully fleshed out, the good news is that we can measure progress empirically and we will know pretty easily whether we’re on the right track (or not).
With enough repetition, we can empirically calculate the Expected Value of our algorithm. For a winning algorithm, we need our expected winners to be bigger than our expected losers.
If Expected Value > 0
⇒ Probability(Winning Bet)*(Average Win) > Probability(Losing Bet)*(Average Loss)
It’s interesting to note that Warren Buffet thinks of his investments in the same way:
“Take the probability of loss times the amount of possible loss from the probability of gain times the amount of possible gain. That is what we're trying to do. It's imperfect, but that's what it's all about.”
-- Warren Buffet
Characteristics of a Winning Algorithm
We have a few different scenarios:

Note: Batting Average is our “Win rate” that is, the percentage of transactions that result in a positive return.
Quadrant NOGO (Low Batting Average and W/L < 1)
If we have a low batting average and a low Win to Loss Ratio, we’re in trouble. We can’t have a positive expected value if we lose more often than we win, and when our losers are bigger than our winners.
Quadrant HOLY GRAIL (High Batting Average and W/L > 1)
This is the holy grail. We win more often than we lose, and we make more on our winners than our losers. Unless one were to make lots of irresponsible outsized bets, if our algorithm falls within this category, it becomes very hard to lose money over time.
Quadrant A (Good Batting Average and W/L < 1)
In this category, we win more often than we lose, but our average loss is greater than our average win. Depending on the relationship between Batting Average and the Win to Loss ratio, an algorithm that falls within this quadrant could certainly work.
Quadrant B (Low Batting Average and W/L > 1)
In this case, even though we have a low batting average, our winners are bigger than our losers. If the winners are big enough, then an algorithm that falls within this quadrant could also result in a positive expected return.
This quadrant is analogous to the Venture Capital model.
Digging A Little Deeper
Expected Return
= (Batting Average)*(Average Win) - (1 - Batting Average)*(Average Loss)
= B*W - (1 - B)*L
For a positive expected return, we need
B*W > (1 - B)*L
⇒ W/L > (1 - B)/B

When we graph this relationship between the W/L ratio vs. the Batting Average, we see that as our batting average goes down, we require significantly higher performance from our winners in order to get to a positive expected value.
If our batting average is only 20%, we require our average winner to be 4X the size of our average loser just to break even!
At a 50% win-rate, we simply need our winners to be bigger than our losers.
At a 60% win-rate, our winners can be 2/3rds the size of our losers and we still break-even.
Designing a Winning Algorithm
Of course, if we can manage to create an algorithm that gets us into the “The Holy Grail” quadrant, we’re golden.
The more likely scenario is we land in one of the “It Could Work” quadrants, namely Quadrant A or B.
For a given batting average, the table below shows us the minimum Win to Loss ratios we need to break even.

If we can achieve a 40% batting average, we then need to make 50% more on our winners than we lose on our losers.
If we can increase that win rate just a little bit, to 45%, then we simply need to make 22% more on our winners than our losers.
Due to the inherent leverage embedded within options, risking $1 to make $1.22 seems not too far fetched.
Perhaps this is a good target to aim for?
Early Results
I started experimenting with an approach earlier this year.
After 69 transactions, the results are as follows

The expected value of the distribution above is 52.86%. Pretty Wild!
A Few Early Takeaways
The Power Law In Action: 23% of outcomes (16) have been massive losers. Despite this, their returns have been dwarfed by just the 2 Grand Slams. We’re seeing the Power Law at work. I believe this is a requirement for our algorithm to be successful.
Too Many Big Losers? To have a high Win/Loss ratio, we need to keep the denominator small (i.e limit our losers). The data shows that almost a quarter of my transactions lost more than 50%. It’s unclear whether this is a feature or a bug...is it necessary to have so many big losers in order to give myself the opportunity for big winners? or is this something I need to improve? Probably a little bit of both...
The Homerun Anomaly: It is interesting to see that there are 9 Homeruns so far. This represents a spike on the right side of the return distribution. Although this is a pleasant surprise, over time, I suspect the number of Homerun outcomes will be fewer than the number of Good or Great outcomes. For now, I’ll take it!
The Power of Catalysts: Catalysts have a profound impact on the magnitude of option price movements. The biggest winner (a ~10 bagger) was an AMD call option that I held into earnings.
A Built-in Buffer: My Win/Loss Ratio is dramatically higher than I expected. With the current ~3.33 ratio, my batting average can drop significantly before I’d become unprofitable. Although the ratio is likely to trend lower over time, I’m glad to see that after 69 transactions, a cushion exists.
Wrapping Up
What I find fascinating about options is that by owning them, I take on a known amount of limited downside risk, but by doing so, I give myself exposure to potentially huge non-linear positive payoffs. In my view, this is exactly what the Venture Capital model is all about.
Unfortunately, this doesn’t come for free. Options are depreciating assets: there is only a limited amount of time during which our potential payoffs can occur.
Above, I wrote that by taking a Venture Capital approach to the stock market, if we are right about the future potential a few businesses, we can benefit immensely from Power Law dynamics and make wonderful returns. Such returns however can often take a long time to materialize.
So I proposed the following question: What if we could compress these time frames?
Well, it’s too early to form any conclusions, but the above early results are intriguing. With the right algorithm, it may be possible.
If you enjoyed this article, share it with a friend, they may like it too!